
Towards Fast Image-Based Localization on a City-Scale
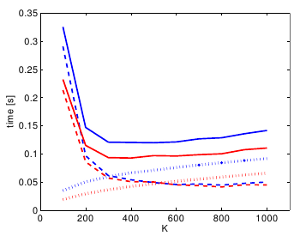
Recent developments in Structure-from-Motion approaches allow the reconstructions of large parts of urban scenes. The available models can in turn be used for accurate image-based localization via pose estimation from 2D-to-3D correspondences. In this paper, we analyze a recently proposed localization method that achieves state-of-the-art localization performance using a visual vocabulary quantization for efficient 2D-to-3D correspondence search. We show that using only a subset of the original models allows the method to achieve a similar localization performance. While this gain can come at additional computational cost depending on the dataset, the reduced model requires significantly less memory, allowing the method to handle even larger datasets. We study how the size of the subset, as well as the quantization, affect both the search for matches and the time needed by RANSAC for pose estimation.
The original publication will be available at www.springerlink.com upon publication.
