
Publications
Dual Loops Meshing: Quality Quad Layouts on Manifolds
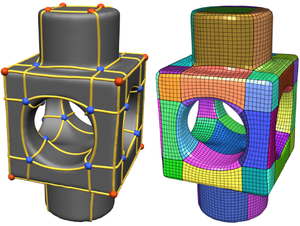
We present a theoretical framework and practical method for the automatic construction of simple, all-quadrilateral patch layouts on manifold surfaces. The resulting layouts are coarse, surface-embedded cell complexes well adapted to the geometric structure, hence they are ideally suited as domains and base complexes for surface parameterization, spline fitting, or subdivision surfaces and can be used to generate quad meshes with a high-level patch structure that are advantageous in many application scenarios. Our approach is based on the careful construction of the layout graph's combinatorial dual. In contrast to the primal this dual perspective provides direct control over the globally interdependent structural constraints inherent to quad layouts. The dual layout is built from curvature-guided, crossing loops on the surface. A novel method to construct these efficiently in a geometry- and structure-aware manner constitutes the core of our approach.
Improving Image-Based Localization by Active Correspondence Search
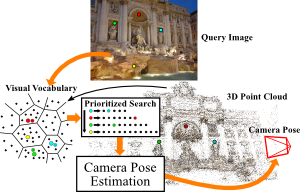
We propose a powerful pipeline for determining the pose of a query image relative to a point cloud reconstruction of a large scene consisting of more than one million 3D points. The key component of our approach is an efficient and effective search method to establish matches between image features and scene points needed for pose estimation. Our main contribution is a framework for actively searching for additional matches, based on both 2D-to-3D and 3D-to-2D search. A unified formulation of search in both directions allows us to exploit the distinct advantages of both strategies, while avoiding their weaknesses. Due to active search, the resulting pipeline is able to close the gap in registration performance observed between efficient search methods and approaches that are allowed to run for multiple seconds, without sacrificing run-time efficiency. Our method achieves the best registration performance published so far on three standard benchmark datasets, with run-times comparable or superior to the fastest state-of-the-art methods.
The original publication will be available at www.springerlink.com upon publication.
Procedural Interpolation of Historical City Maps
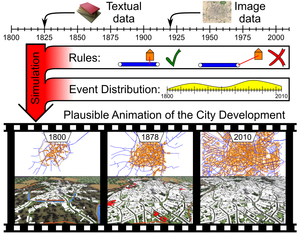
We propose a novel approach for the temporal interpolation of city maps. The input to our algorithm is a sparse set of historical city maps plus optional additional knowledge about construction or destruction events. The output is a fast forward animation of the city map development where roads and buildings are constructed and destroyed over time in order to match the sparse historical facts and to look plausible where no precise facts are available. A smooth transition between any real-world data could be interesting for educational purposes, because our system conveys an intuition of the city development. The insertion of data, like when and where a certain building or road existed, is efficiently performed by an intuitive graphical user interface. Our system collects all this information into a global dependency graph of events. By propagating time intervals through the dependency graph we can automatically derive the earliest and latest possible date for each event which are guaranteeing temporal as well as geographical consistency (e.g. buildings can only appear along roads that have been constructed before). During the simulation of the city development, events are scheduled according to a score function that rates the plausibility of the development (e.g. cities grow along major roads). Finally, the events are properly distributed over time to control the dynamics of the city development. Based on the city map animation we create a procedural city model in order to render a 3D animation of the city development over decades.
Rationalization of Triangle-Based Point-Folding Structures

In mechanical engineering and architecture, structural elements with low material consumption and high load-bearing capabilities are essential for light-weight and even self-supporting constructions. This paper deals with so called point-folding elements - non-planar, pyramidal panels, usually formed from thin metal sheets, which exploit the increased structural capabilities emerging from folds or creases. Given a triangulated free-form surface, a corresponding point-folding structure is a collection of pyramidal elements basing on the triangles. User-specified or material-induced geometric constraints often imply that each individual folding element has a different shape, leading to immense fabrication costs. We present a rationalization method for such structures which respects the prescribed aesthetic and production constraints and ?nds a minimal set of molds for the production process, leading to drastically reduced costs. For each base triangle we compute and parametrize the range of feasible folding elements that satisfy the given constraints within the allowed tolerances. Then we pose the rationalization task as a geometric intersection problem, which we solve so as to maximize the re-use of mold dies. Major challenges arise from the high precision requirements and the non-trivial parametrization of the search space. We evaluate our method on a number of practical examples where we achieve rationalization gains of more than 90%.
Linear Analysis of Nonlinear Constraints for Interactive Geometric Modeling
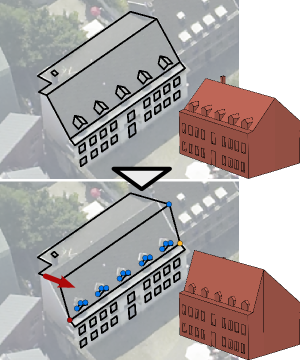
Thanks to its flexibility and power to handle even complex geometric relations, 3D geometric modeling with nonlinear constraints is an attractive extension of traditional shape editing approaches. However, existing approaches to analyze and solve constraint systems usually fail to meet the two main challenges of an interactive 3D modeling system: For each atomic editing operation, it is crucial to adjust as few auxiliary vertices as possible in order to not destroy the user's earlier editing effort. Furthermore, the whole constraint resolution pipeline is required to run in real-time to enable a fluent, interactive workflow. To address both issues, we propose a novel constraint analysis and solution scheme based on a key observation: While the computation of actual vertex positions requires nonlinear techniques, under few simplifying assumptions the determination of the minimal set of to-be-updated vertices can be performed on a linearization of the constraint functions. Posing the constraint analysis phase as the solution of an under-determined linear system with as few non-zero elements as possible enables us to exploit an efficient strategy for the Cardinality Minimization problem known from the field of Compressed Sensing, resulting in an algorithm capable of handling hundreds of vertices and constraints in real-time. We demonstrate at the example of an image-based modeling system for architectural models that this approach performs very well in practical applications.
Awards:
A Practical Guide to Polygon Mesh Repairing
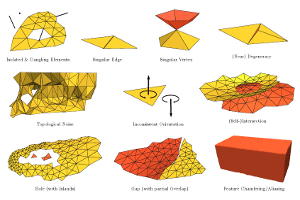
Digital 3D models are key components in many industrial and scientific sectors. In numerous domains polygon meshes have become a de facto standard for model representation. In practice meshes often have a number of defects and flaws that make them incompatible with quality requirements of specific applications. Hence, repairing such defects in order to achieve compatibility is a highly important task – in academic as well as industrial applications. In this tutorial we first systematically analyze typical application contexts together with their requirements and issues, as well as the various types of defects that typically play a role. Subsequently, we consider existing techniques to process, repair, and improve the structure, geometry, and topology of imperfect meshes, aiming at making them appropriate to case-by-case requirements. We present seminal works and key algorithms, discuss extensions and improvements, and analyze the respective advantages and disadvantages depending on the application context. Furthermore, we outline directions where further research is particularly important or promising.
Using Spherical Harmonics for Modeling Antenna Patterns
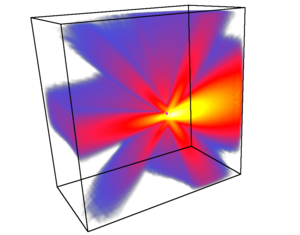
In radio wave propagation simulations there is a need for modeling antenna patterns. Both the transmitting and the receiving antenna influence the wireless link. We use spherical harmonics to compress the amount of measured data needed for complex antenna patterns. We present a method to efficiently incorporate these patterns into a ray tracing framework for radio wave propagation. We show how to efficiently generate rays according to the transmitting antenna pattern. The ray tracing simulation computes a compressed irradiance field for every point in the scene. The receiving antenna pattern can then be applied to this field for the final estimation of signal strength.
Topology aware Quad Dominant Meshing for Vascular Structures
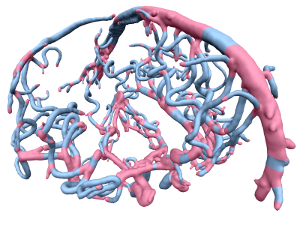
We present a pipeline to generate high quality quad dominant meshes for vascular structures from a given volumetric image. As common for medical image segmentation we use a Level Set approach to separate the region of interest from the background. However in contrast to the standard method we control the topology of the deformable object – defined by the Level Set function – which allows us to extract a proper skeleton which represents the global topological information of the vascular structure. Instead of solving a complex global optimization problem to compute a quad mesh, we divide the problem and partition the complex model into junction and tube elements, employing the skeleton of the vascular structure. After computing quad meshes for the junctions using the Mixed Integer Quadrangulation approach, we re-mesh the tubes using an algorithm inspired by the well known Bresenham Algorithm for drawing lines which distributes irregular elements equally over the entire tube element.
Interactive Modeling by Procedural High-Level Primitives
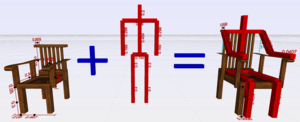
Procedural modeling is a promising approach to create complex and detailed 3D objects and scenes. Based on the concept of split grammars, e.g., construction rules can be defined textually in order to describe a hierarchical build-up of a scene. Unfortunately, creating or even just reading such grammars can become very challenging for non-programmers. Recent approaches have demonstrated ideas to interactively control basic split operations for boxes, however, designers need to have a deep understanding of how to express a certain object by just using box splitting. Moreover, the degrees of freedom of a certain model are typically very high and thus the adjustment of parameters remains more or less a trial-and-error process. In our paper, we therefore present novel concepts for the intuitive and interactive handling of complex procedural grammars allowing even amateurs and non-programmers to easily modify and combine existing procedural models that are not limited to the subdivision of boxes. In our grammar 3D manipulators can be defined in order to spawn a visual representation of adjustable parameters directly in model space to reveal the influence of a parameter. Additionally, modules of the procedural grammar can be associated with a set of camera views which draw the user's attention to a specific subset of relevant parameters and manipulators. All these concepts are encapsulated into procedural high-level primitives that effectively support the efficient creation of complex procedural 3D scenes. Since our target group are mainly users without any experience in 3D modeling, we prove the usability of our system by letting some untrained students perform a modeling task from scratch.
A Framework for Vision-based Mobile AR Applications
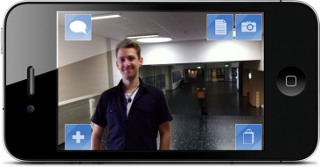
This paper analyzes the requirements for a general purpose mobile Augmented Reality framework that supports expert as well as non-expert authors to create customized mobile AR applications. A key component is the use of image based localization performed on a central server. It further describes an implementation of such a framework as well as an example application created in this framework to demonstrate the practicability of the described design.
Dynamic Tiling Display: Building an Interactive Display Surface using Multiple Mobile Devices
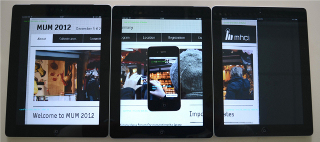
Table display surfaces, like Microsoft PixelSense, can display multimedia content to a group of users simultaneously, but it is expensive and lacks mobility. On the contrary, mobile devices are more easily available, but due to limited screen size and resolution, they are not suitable for sharing multimedia data interactively. In this paper we present a "Dynamic Tiling Display", an interactive display surface built from mobile devices. Our framework utilizes the integrated front facing camera of mobile devices to estimate the relative pose of multiple mobile screens arbitrarily placed on a table. Using this framework, users can create a large virtual display where multiple users can explore multimedia data interactively through separate windows (mobile screens). The major technical challenge is the calibration of individual displays, which is solved by visual object recognition using front facing camera inputs.
Best Paper Award in MUM12
Image Retrieval for Image-Based Localization Revisited
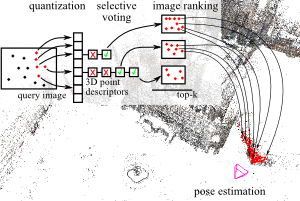
To reliably determine the camera pose of an image relative to a 3D point cloud of a scene, correspondences between 2D features and 3D points are needed. Recent work has demonstrated that directly matching the features against the points outperforms methods that take an intermediate image retrieval step in terms of the number of images that can be localized successfully. Yet, direct matching is inherently less scalable than retrieval-based approaches. In this paper, we therefore analyze the algorithmic factors that cause the performance gap and identify false positive votes as the main source of the gap. Based on a detailed experimental evaluation, we show that retrieval methods using a selective voting scheme are able to outperform state-of-the-art direct matching methods. We explore how both selective voting and correspondence computation can be accelerated by using a Hamming embedding of feature descriptors. Furthermore, we introduce a new dataset with challenging query images for the evaluation of image-based localization.
Variational Tangent Plane Intersection for Planar Polygonal Meshing
Several theoretical and practical geometry applications are based on polygon meshes with planar faces. The planar panelization of freeform surfaces is a prominent example from the field of architectural geometry. One approach to obtain a certain kind of such meshes is by intersection of suitably distributed tangent planes. Unfortunately, this simple tangent plane intersection (TPI) idea is limited to the generation of hex-dominant meshes: as vertices are in general defined by three intersecting planes, the resulting meshes are basically duals of triangle meshes.
The explicit computation of intersection points furthermore requires dedicated handling of special cases and degenerate constellations to achieve robustness on freeform surfaces. Another limitation is the small number of degrees of freedom for incorporating design parameters.
Using a variational re-formulation, we equip the concept of TPI with additional degrees of freedom and present a robust, unified approach for creating polygonal structures with planar faces that is readily able to integrate various objectives and constraints needed in different applications scenarios. We exemplarily demonstrate the abilities of our approach on three common problems in geometry processing.
Practical Mixed-Integer Optimization for Geometry Processing
Proceedings of Curves and Surfaces 2010
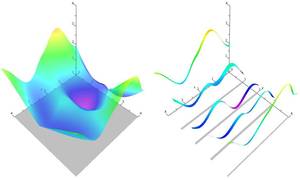
Solving mixed-integer problems, i.e., optimization problems where some of the unknowns are continuous while others are discrete, is NP-hard. Unfortunately, real-world problems like e.g., quadrangular remeshing usually have a large number of unknowns such that exact methods become unfeasible. In this article we present a greedy strategy to rapidly approximate the solution of large quadratic mixed-integer problems within a practically sufficient accuracy. The algorithm, which is freely available as an open source library implemented in C++, determines the values of the discrete variables by successively solving relaxed problems. Additionally the specification of arbitrary linear equality constraints which typically arise as side conditions of the optimization problem is possible. The performance of the base algorithm is strongly improved by two novel extensions which are (1) simultaneously estimating sets of discrete variables which do not interfere and (2) a fill-in reducing reordering of the constraints. Exemplarily the solver is applied to the problem of quadrilateral surface remeshing, enabling a great flexibility by supporting different types of user guidance within a real-time modeling framework for input surfaces of moderate complexity.
Insights into user experiences and acceptance of mobile indoor navigation devices
Location-based services, which can be applied in navigation systems, are a key application in mobile and ubiquitous computing. Combined with indoor localization techniques, pico projectors can be used for navigation purposes to augment the environment with navigation information. In the present empirical study (n = 24) we explore users’ perceptions, workload and navigation performance when navigating with a mobile projector in comparison to a mobile screen as indoor navigation interface. To capture user perceptions and to predict acceptance by applying structural equation modeling, we assessed perceived disorientation, privacy concerns, trust, ease of use, usefulness, and sources of visibility problems. Moreover, the impact of user factors (spatial abilities, technical self-efficacy, familiarity) on acceptance was analyzed. The structural models exhibited adequate predictive and psychometric properties. Based on real user experience, they clearly pointed out a) similarities and device-specific differences in navigation device acceptance, b) the role of specific user experiences (visibility, trust, and disorientation) during navigation device usage and c) illuminated the underlying relationships between determinants of user acceptance. Practical implications of the results and future research questions are provided.
OpenVolumeMesh - A Versatile Index-Based Data Structure for 3D Polytopal Complexes
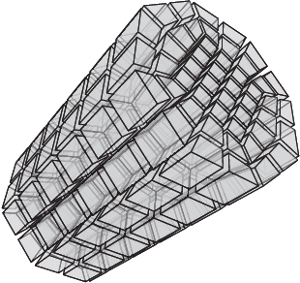
OpenVolumeMesh is a data structure which is able to represent heterogeneous 3-dimensional polytopal cell complexes and is general enough to also represent non- manifolds without incurring undue overhead. Extending the idea of half-edge based data structures for two-manifold surface meshes, all faces, i.e. the two-dimensional entities of a mesh, are represented by a pair of oriented half-faces. The concept of using directed half-entities enables inducing an orientation to the meshes in an intuitive and easy to use manner. We pursue the idea of encoding connectivity by storing first-order top-down incidence relations per entity, i.e. for each entity of dimension d, a list of links to the respective incident entities of dimension d?1 is stored. For instance, each half-face as well as its orientation is uniquely determined by a tuple of links to its incident half- edges or each 3D cell by the set of incident half-faces. This representation allows for handling non-manifolds as well as mixed-dimensional mesh configurations. No entity is duplicated according to its valence, instead, it is shared by all incident entities in order to reduce memory consumption. Furthermore, an array-based storage layout is used in combination with direct index-based access. This guarantees constant access time to the entities of a mesh. Although bottom-up incidence relations are implied by the top-down incidences, our data structure provides the option to explicitly generate and cache them in a transparent manner. This allows for accelerated navigation in the local neighbor- hood of an entity. We provide an open-source and platform-independent implementation of the proposed data structure written in C++ using dynamic typing paradigms. The li- brary is equipped with a set of STL compliant iterators, a generic property system to dynamically attach properties to all entities at run-time, and a serializer/deseri- alizer supporting a simple file format. Due to its similarity to the OpenMesh data structure, it is easy to use, in particular for those familiar with OpenMesh. Since the presented data structure is compact, intuitive, and efficient, it is suitable for a variety of applications, such as meshing, visualization, and numerical analysis. OpenVolumeMesh is open-source software licensed under the terms of the LGPL.
Golden Ratio Sequences for Low-Discrepancy Sampling

Most classical constructions of low-discrepancy point sets are based on generalizations of the one-dimensional binary van der Corput sequence, whose implementation requires nontrivial bit-operations. As an alternative, we introduce the quasi-regular golden ratio sequences, which are based on the fractional part of successive integer multiples of the golden ratio. By leveraging results from number theory, we show that point sets, which evenly cover the unit square or disc, can be computed by a simple incremental permutation of a generator golden ratio sequence. We compare ambient occlusion images generated with a Monte Carlo ray tracer based on random, Hammersley, blue noise, and golden ratio point sets. The source code of the ray tracer used for our experiments is available online at the address provided at the end of this article.
The Design of a Segway AR-Tactile Navigation System

A Segway is often used to transport a user across mid range distances in urban environments. It has more degrees of freedom than car/bike and is faster than pedestrian. However a navigation system designed for it has not been researched. The existing navigation systems are adapted for car drivers or pedestrians. Using such systems on the Segway can increase the driver’s cognitive workload and generate safety risks. In this paper, we present a Segway AR-Tactile navigation system, in which we visualize the route through an Augmented Reality interface displayed by a mobile phone. The turning instructions are presented to the driver via vibro-tactile actuators attached to the handlebar. Multiple vibro-tactile patterns provide navigation instructions. We evaluate the system in real traffic and an artificial environment. Our results show the AR interface reduces users’ subjective workload significantly. The vibro-tactile patterns can be perceived correctly and greatly improve the driving performance.
Towards Fast Image-Based Localization on a City-Scale
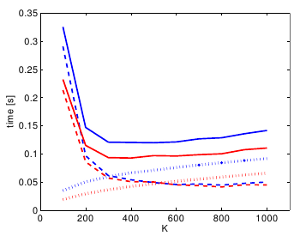
Recent developments in Structure-from-Motion approaches allow the reconstructions of large parts of urban scenes. The available models can in turn be used for accurate image-based localization via pose estimation from 2D-to-3D correspondences. In this paper, we analyze a recently proposed localization method that achieves state-of-the-art localization performance using a visual vocabulary quantization for efficient 2D-to-3D correspondence search. We show that using only a subset of the original models allows the method to achieve a similar localization performance. While this gain can come at additional computational cost depending on the dataset, the reduced model requires significantly less memory, allowing the method to handle even larger datasets. We study how the size of the subset, as well as the quantization, affect both the search for matches and the time needed by RANSAC for pose estimation.
The original publication will be available at www.springerlink.com upon publication.
Previous Year (2011)
