
Profile

|
Dr. Lars Krecklau |
Publications
View-Dependent Realtime Rendering of Procedural Facades with High Geometric Detail

We present an algorithm for realtime rendering of large-scale city models with procedurally generated facades. By using highly detailed assets like windows, doors, and decoration such city models can provide an extremely high geometric level of detail but on the downside they also consist of billions of polygons which makes it infeasible to even store them as explicit polygonal meshes. Moreover, when rendering urban scenes usually only a very small fraction of the city is actually visible which calls for effective culling mechanisms. For procedural textures there are efficient screen space techniques that evaluate, e.g., a split grammar on a per-pixel basis in the fragment shader and thus render a textured facade in a view dependent manner. We take this idea further by introducing 3D geometric detail in addition to flat textures. Our approach is a two-pass procedure that first renders a flat procedural facade. During rasterization the fragment shader triggers the instantiation of a detailed asset whenever a geometric facade element is potentially visible. The set of instantiated detail models are then rendered in a second pass. The major challenges arise from the fact that geometric details belonging to a facade can be visible even if the base polygon of the facade itself is not visible. Hence we propose measures to conservatively estimate visibility without introducing excessive redundancy. We further extend our technique by a simple level of detail mechanism that switches to baked textures (of the assets) depending on the distance to the camera. We demonstrate that our technique achieves realtime frame rates for large-scale city models with massive detail on current commodity graphics hardware.
Procedural Interpolation of Historical City Maps
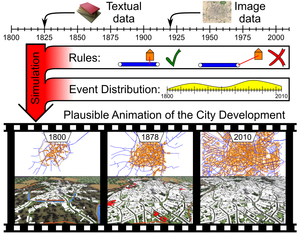
We propose a novel approach for the temporal interpolation of city maps. The input to our algorithm is a sparse set of historical city maps plus optional additional knowledge about construction or destruction events. The output is a fast forward animation of the city map development where roads and buildings are constructed and destroyed over time in order to match the sparse historical facts and to look plausible where no precise facts are available. A smooth transition between any real-world data could be interesting for educational purposes, because our system conveys an intuition of the city development. The insertion of data, like when and where a certain building or road existed, is efficiently performed by an intuitive graphical user interface. Our system collects all this information into a global dependency graph of events. By propagating time intervals through the dependency graph we can automatically derive the earliest and latest possible date for each event which are guaranteeing temporal as well as geographical consistency (e.g. buildings can only appear along roads that have been constructed before). During the simulation of the city development, events are scheduled according to a score function that rates the plausibility of the development (e.g. cities grow along major roads). Finally, the events are properly distributed over time to control the dynamics of the city development. Based on the city map animation we create a procedural city model in order to render a 3D animation of the city development over decades.
Interactive Modeling by Procedural High-Level Primitives
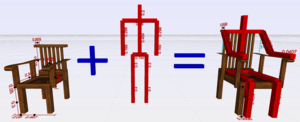
Procedural modeling is a promising approach to create complex and detailed 3D objects and scenes. Based on the concept of split grammars, e.g., construction rules can be defined textually in order to describe a hierarchical build-up of a scene. Unfortunately, creating or even just reading such grammars can become very challenging for non-programmers. Recent approaches have demonstrated ideas to interactively control basic split operations for boxes, however, designers need to have a deep understanding of how to express a certain object by just using box splitting. Moreover, the degrees of freedom of a certain model are typically very high and thus the adjustment of parameters remains more or less a trial-and-error process. In our paper, we therefore present novel concepts for the intuitive and interactive handling of complex procedural grammars allowing even amateurs and non-programmers to easily modify and combine existing procedural models that are not limited to the subdivision of boxes. In our grammar 3D manipulators can be defined in order to spawn a visual representation of adjustable parameters directly in model space to reveal the influence of a parameter. Additionally, modules of the procedural grammar can be associated with a set of camera views which draw the user's attention to a specific subset of relevant parameters and manipulators. All these concepts are encapsulated into procedural high-level primitives that effectively support the efficient creation of complex procedural 3D scenes. Since our target group are mainly users without any experience in 3D modeling, we prove the usability of our system by letting some untrained students perform a modeling task from scratch.
Procedural Modeling of Interconnected Structures

The complexity and detail of geometric scenes that are used in today's computer animated films and interactive games have reached a level where the manual creation by traditional 3D modeling tools has become infeasible. This is why procedural modeling concepts have been developed which generate highly complex 3D models by automatically executing a set of formal construction rules. Well-known examples are variants of L-systems which describe the bottom-up growth process of plants and shape grammars which define architectural buildings by decomposing blocks in a top-down fashion. However, none of these approaches allows for the easy generation of interconnected structures such as bridges or roller coasters where a functional interaction between rigid and deformable parts of an object is needed. Our approach mainly relies on the top-down decomposition principle of shape grammars to create an arbitrarily complex but well structured layout. During this process, potential attaching points are collected in containers which represent the set of candidates to establish interconnections. Our grammar then uses either abstract connection patterns or geometric queries to determine elements in those containers that are to be connected. The two different types of connections that our system supports are rigid object chains and deformable beams. The former type is constructed by inverse kinematics, the latter by spline interpolation. We demonstrate the descriptive power of our grammar by example models of bridges, roller coasters, and wall-mounted catenaries.
Realtime Compositing of Procedural Facade Textures on the GPU

The real time rendering of complex virtual city models has become more important in the last few years for many practical applications like realistic navigation or urban planning. For maximum rendering performance, the complexity of the geometry or textures can be reduced by decreasing the resolution until the data set can fully reside on the memory of the graphics card. This typically results in a low quality of the virtual city model. Alternatively, a streaming algorithm can load the high quality data set from the hard drive. However, this approach requires a large amount of persistent storage providing several gigabytes of static data. We present a system that uses a texture atlas containing atomic tiles like windows, doors or wall patterns, and that combines those elements on-the-fly directly on the graphics card. The presented approach benefits from a sophisticated randomization approach that produces lots of different facades while the grammar description itself remains small. By using a ray casting apporach, we are able to trace through transparent windows revealing procedurally generated rooms which further contributes to the realism of the rendering. The presented method enables real time rendering of city models with a high level of detail for facades while still relying on a small memory footprint.
Generalized Use of Non-Terminal Symbols for Procedural Modeling

We present the new procedural modeling language G² (Generalized Grammar) which adapts various concepts from general purpose programming languages in order to provide high descriptive power with well-defined semantics and a simple syntax which is easily readable even by non-programmers. We extend the scope of previous architectural modeling languages by allowing for multiple types of non-terminal objects with domain-specific operators and attributes. The language accepts non-terminal symbols as parameters in modeling rules and thus enables the definition of abstract structure templates for flexible re-use within the grammar. To identify specific scene parts or objects, we introduce flags which are Boolean values whose scope covers an entire subtree in the scenegraph. The rigorous handling of typed parameters which are locally declared within the rules prevents inconsistent states emerging from not or wrongly declared variables. By deriving G² from the well-established programming language Python, we can make sure that our modeling language has a well-defined semantics. For illustration, we apply G² to architectural as well as plant modeling in order to demonstrate its descriptive power with some complex examples.
We also provide a Python prototype related to this paper for an easy integration of our system into the Houdini modeling framework from SideFX software. It is available on the project page.
2D Video Editing for 3D Effects

We present a semi-interactive system for advanced video processing and editing. The basic idea is to partially recover planar regions in object space and to exploit this minimal pseudo-3D information in order to make perspectively correct modifications. Typical operations are to increase the quality of a low-resolution video by overlaying high-resolution photos of the same approximately planar object or to add or remove objects by copying them from other video streams and distorting them perspectively according to some planar reference geometry. The necessary user interaction is entirely in 2D and easy to perform even for untrained users. The key to our video processing functionality is a very robust and mostly automatic algorithm for the perspective registration of video frames and photos, which can be used as a very effective video stabilization tool even in the presence of fast and blurred motion. Explicit 3D reconstruction is thus avoided and replaced by image and video rectification. The technique is based on state-of-the-art feature tracking and homography matching. In complicated and ambiguous scenes, user interaction as simple as 2D brush strokes can be used to support the registration. In the stabilized video, he reference plane appears frozen which simplifies segmentation and matte extraction. We demonstrate our system for a number of quite challenging application scenarios such as video enhancement, background replacement, foreground removal and perspectively correct video cut and paste.
City Virtualization

Virtual city models become more and more important in applications like virtual city guides, geographic information systems or large scale visualizations, and also play an important role during the design of wireless networks and the simulation of noise distribution or environmental phenomena. However, generating city models of sufficient quality with respect to different target applications is still an extremely challenging, time consuming and costly process. To improve this situation, we present a novel system for the rapid and easy creation of 3D city models from 2D map data and terrain information, which is available for many cities in digital form. Our system allows to continuously vary the resulting level of correctness, ranging from models with high-quality geometry and plausible appearance which are generated almost completely automatic to models with correctly textured facades and highly detailed representations of important, well known buildings which can be generated with reasonable additional effort. While our main target application is the high-quality, real-time visualization of complex, detailed city models, the models generated with our approach have successfully been used for radio wave simulations as well. To demonstrate the validity of our approach, we show an exemplary reconstruction of the city of Aachen.
