
Profile

|
Dr. Alexander Hornung |
Publications
Character Reconstruction and Animation from Uncalibrated Video

We present a novel method to reconstruct 3D character models from video. The main conceptual contribution is that the reconstruction can be performed from a single uncalibrated video sequence which shows the character in articulated motion. We reduce this generalized problem setting to the easier case of multi-view reconstruction of a rigid scene by applying pose synchronization of the character between frames. This is enabled by two central technical contributions. First, based on a generic character shape template, a new mesh-based technique for accurate shape tracking is proposed. This method successfully handles the complex occlusions issues, which occur when tracking the motion of an articulated character. Secondly, we show that image-based 3D reconstruction becomes possible by deforming the tracked character shapes as-rigid-as-possible into a common pose using motion capture data. After pose synchronization, several partial reconstructions can be merged in order to create a single, consistent 3D character model. We integrated these components into a simple interactive framework, which allows for straightforward generation and animation of 3D models for a variety of character shapes from uncalibrated monocular video.
Image Selection For Improved Multi-View Stereo

The Middlebury Multi-View Stereo evaluation clearly shows that the quality and speed of most multi-view stereo algorithms depends significantly on the number and selection of input images. In general, not all input images contribute equally to the quality of the output model, since several images may often contain similar and hence overly redundant visual information. This leads to unnecessarily increased processing times. On the other hand, a certain degree of redundancy can help to improve the reconstruction in more ``difficult'' regions of a model. In this paper we propose an image selection scheme for multi-view stereo which results in improved reconstruction quality compared to uniformly distributed views. Our method is tuned towards the typical requirements of current multi-view stereo algorithms, and is based on the idea of incrementally selecting images so that the overall coverage of a simultaneously generated proxy is guaranteed without adding too much redundant information. Critical regions such as cavities are detected by an estimate of the local photo-consistency and are improved by adding additional views. Our method is highly efficient, since most computations can be out-sourced to the GPU. We evaluate our method with four different methods participating in the Middlebury benchmark and show that in each case reconstructions based on our selected images yield an improved output quality while at the same time reducing the processing time considerably.
City Virtualization

Virtual city models become more and more important in applications like virtual city guides, geographic information systems or large scale visualizations, and also play an important role during the design of wireless networks and the simulation of noise distribution or environmental phenomena. However, generating city models of sufficient quality with respect to different target applications is still an extremely challenging, time consuming and costly process. To improve this situation, we present a novel system for the rapid and easy creation of 3D city models from 2D map data and terrain information, which is available for many cities in digital form. Our system allows to continuously vary the resulting level of correctness, ranging from models with high-quality geometry and plausible appearance which are generated almost completely automatic to models with correctly textured facades and highly detailed representations of important, well known buildings which can be generated with reasonable additional effort. While our main target application is the high-quality, real-time visualization of complex, detailed city models, the models generated with our approach have successfully been used for radio wave simulations as well. To demonstrate the validity of our approach, we show an exemplary reconstruction of the city of Aachen.
Character Animation from 2D Pictures and 3D Motion Data

This paper presents a new method to animate photos of 2D characters using 3D motion capture data. Given a single image of a person or essentially human-like subject our method transfers the motion of a 3D skeleton onto the subject's 2D shape in image space, generating the impression of a realistic movement. We present robust solutions to reconstruct a projective camera model and a 3D model pose which matches best to the given 2D image. Depending on the reconstructed view, a 2D shape template is selected which enables the proper handling of occlusions. After fitting the template to the character in the input image, it is deformed as-rigid-as-possible by taking the projected 3D motion data into account. Unlike previous work our method thereby correctly handles projective shape distortion. It works for images from arbitrary views and requires only a small amount of user interaction. We present animations of a diverse set of human (and non-human) characters with different types of motions such as walking, jumping, or dancing.
Robust Reconstruction of Watertight 3D Models from Non-uniformly Sampled Point Clouds Without Normal Information

We present a new volumetric method for reconstructing watertight triangle meshes from arbitrary, unoriented point clouds. While previous techniques usually reconstruct surfaces as the zero level-set of a signed distance function, our method uses an unsigned distance function and hence does not require any information about the local surface orientation. Our algorithm estimates local surface confidence values within a dilated crust around the input samples. The surface which maximizes the global confidence is then extracted by computing the minimum cut of a weighted spatial graph structure. We present an algorithm, which efficiently converts this cut into a closed, manifold triangle mesh with a minimal number of vertices. The use of an unsigned distance function avoids the topological noise artifacts caused by misalignment of 3D scans, which are common to most volumetric reconstruction techniques. Due to a hierarchical approach our method efficiently produces solid models of low genus even for noisy and highly irregular data containing large holes, without loosing fine details in densely sampled regions. We show several examples for different application settings such as model generation from raw laser-scanned data, image-based 3D reconstruction, and mesh repair.
Hierarchical Volumetric Multi-view Stereo Reconstruction of Manifold Surfaces based on Dual Graph Embedding

This paper presents a new volumetric stereo algorithm to reconstruct the 3D shape of an arbitrary object. Our method is based on finding the minimum cut in an octahedral graph structure embedded into the vol umetric grid, which establishes a well defined relationship between the integrated photo-consistency function of a region in space and the corresponding edge weights of the embedded graph. This new graph structure allows for a highly efficient hierarchical implementation supporting high volumetric resolutions and large numbers of input images. Furthermore we will show how the resulting cut surface can be directly converted into a consistent, closed and manifold mesh. Hence this work provides a complete multi-view stereo reconstruction pipeline. We demonstrate the robustness and efficiency of our technique by a number of high quality reconstructions of real objects.
Robust and Efficient Photo-Consistency Estimation for Volumetric 3D Reconstruction

Estimating photo-consistency is one of the most important ingredients for any 3D stereo reconstruction technique that is based on a volumetric scene representation. This paper presents a new, illumination invariant photo-consistency measure for high quality, volumetric 3D reconstruction from calibrated images. In contrast to current standard methods such as normalized cross-correlation it supports unconstrained camera setups and non-planar surface approximations. We show how this measure can be embedded into a highly efficient, completely hardware accelerated volumetric reconstruction pipeline by exploiting current graphics processors. We provide examples of high quality reconstructions with computation times of only a few seconds to minutes, even for large numbers of cameras and high volumetric resolutions.
High-Quality Surface Splatting on Today's GPUs

Because of their conceptual simplicity and superior flexibility, point-based geometries evolved into a valuable alternative to surface representations based on polygonal meshes. Elliptical surface splats were shown to allow for high-quality anti-aliased rendering by sophisticated EWA filtering. Since the publication of the original software-based EWA splatting, several authors tried to map this technique to the GPU in order to exploit hardware acceleration. Due to the lacking support for splat primitives, these methods always have to find a trade-off between rendering quality and rendering performance. In this paper, we discuss the capabilities of today's GPUs for hardware-accelerated surface splatting. We present an approach that achieves a quality comparable to the original EWA splatting at a rate of more than 20M elliptical splats per second. In contrast to previous GPU renderers, our method provides per-pixel Phong shading even for dynamically changing geometries and high-quality anti-aliasing by employing a screen-space pre-filter in addition to the object-space reconstruction filter. The use of deferred shading techniques effectively avoids unnecessary shader computations and additionally provides a clear separation between the rasterization and the shading of elliptical splats, which considerably simplifies the development of custom shaders. We demonstrate quality, efficiency, and flexibility of our approach by showing several shaders on a range of models.
Self-Calibrating Optical Motion Tracking for Articulated Bodies
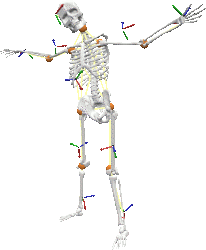
Building intuitive user-interfaces for Virtual Reality applications is a difficult task, as one of the main purposes is to provide a ''natural'', yet efficient input device to interact with the virtual environment. One particularly interesting approach is to track and retarget the complete motion of a subject. Established techniques for full body motion capture like optical motion tracking exist. However, due to their computational complexity and their reliance on pre-specified models, they fail to meet the demanding requirements of Virtual Reality environments such as real-time response, immersion, and ad hoc configurability. Our goal is to support the use of motion capture as a general input device for Virtual Reality applications. In this paper we present a self-calibrating framework for optical motion capture, enabling the reconstruction and tracking of arbitrary articulated objects in real-time. Our method automatically estimates all relevant model parameters on-the-fly without any information on the initial tracking setup or the marker distribution, and computes the geometry and topology of multiple tracked skeletons. Moreover, we show how the model can make the motion capture phase robust against marker occlusions by exploiting the redundancy in the skeleton model and by reconstructing missing inner limbs and joints of the subject from partial information. Meeting the above requirements our system is well applicable to a wide range of Virtual Reality based applications, where unconstrained tracking and flexible retargeting of motion data is desirable.
