
Profile

|
Publications
Two-Colored Pixels

In this paper we show how to use two-colored pixels as a generic tool for image processing. We apply two-colored pixels as a basic operator as well as a supporting data structure for several image processing applications. Traditionally, images are represented by a regular grid of square pixels with one constant color each. In the two-colored pixel representation, we reduce the image resolution and replace blocks of NxN pixels by one square that is split by a (feature) line into two regions with constant colors. We show how the conversion of standard mono-colored pixel images into two-colored pixel images can be computed efficiently by applying a hierarchical algorithm along with a CUDA-based implementation. Two-colored pixels overcome some of the limitations that classical pixel representations have, and their feature lines provide minimal geometric information about the underlying image region that can be effectively exploited for a number of applications. We show how to use two-colored pixels as an interactive brush tool, achieving realtime performance for image abstraction and non-photorealistic filtering. Additionally, we propose a realtime solution for image retargeting, defined as a linear minimization problem on a regular or even adaptive two-colored pixel image. The concept of two-colored pixels can be easily extended to a video volume, and we demonstrate this for the example of video retargeting.
Image Synthesis for Branching Structures

We present a set of techniques for the synthesis of artificial images that depict branching structures like rivers, cracks, lightning, mountain ranges, or blood vessels. The central idea is to build a statistical model that captures the characteristic bending and branching structure from example images. Then a new skeleton structure is synthesized and the final output image is composed from image fragments of the original input images. The synthesis part of our algorithm runs mostly automatic but it optionally allows the user to control the process in order to achieve a specific result. The combination of the statistical bending and branching model with sophisticated fragment-based image synthesis corresponds to a multi-resolution decomposition of the underlying branching structure into the low frequency behavior (captured by the statistical model) and the high frequency detail (captured by the image detail in the fragments). This approach allows for the synthesis of realistic branching structures, while at the same time preserving important textural details from the original image.
Generalized Use of Non-Terminal Symbols for Procedural Modeling

We present the new procedural modeling language G² (Generalized Grammar) which adapts various concepts from general purpose programming languages in order to provide high descriptive power with well-defined semantics and a simple syntax which is easily readable even by non-programmers. We extend the scope of previous architectural modeling languages by allowing for multiple types of non-terminal objects with domain-specific operators and attributes. The language accepts non-terminal symbols as parameters in modeling rules and thus enables the definition of abstract structure templates for flexible re-use within the grammar. To identify specific scene parts or objects, we introduce flags which are Boolean values whose scope covers an entire subtree in the scenegraph. The rigorous handling of typed parameters which are locally declared within the rules prevents inconsistent states emerging from not or wrongly declared variables. By deriving G² from the well-established programming language Python, we can make sure that our modeling language has a well-defined semantics. For illustration, we apply G² to architectural as well as plant modeling in order to demonstrate its descriptive power with some complex examples.
We also provide a Python prototype related to this paper for an easy integration of our system into the Houdini modeling framework from SideFX software. It is available on the project page.
Hybrid Booleans
Talk at Eurographics 2011
In this paper we present a novel method to compute Boolean operation polygonal meshes. Given a Boolean expression over an arbitrary number input meshes we reliably and efficiently compute an output mesh which faithfully preserves the existing sharp features and precisely reconstructs the new features appearing along the intersections of the input meshes. The term "hybrid" applies to our method in two ways: First, our algorithm operates on a hybrid data structure which stores the original input polygons (surface data) in an adaptively refined octree (volume data). By this we combine the robustness of volumetric techniques with the accuracy of surface-oriented techniques. Second, we generate a new triangulation only in a close vicinity around the intersections of the input meshes and thus preserve as much of the original mesh structure as possible (hybrid mesh). Since the actual processing of the Boolean operation is confined to a very small region around the intersections of the input meshes, we can achieve very high adaptive refinement resolutions and hence very high precision. We demonstrate our method on a number of challenging examples.
GIzMOs: Genuine Image Mosaics with Adaptive Tiling

We present a method which splits an input image into a set of tiles. Each tile is then replaced by another image from a large database such that, when viewed from a distance, the original image is reproduced as well as possible. While the general concept of image mosaics is not new, we consider our results as "genuine image mosaics" (or short GIzMOs) in the sense that the images from the database are not modified in any way. This is different from previous work, where the image tiles are usually color shifted or overlaid with the high-frequency content of the input image. Besides the regular alignment of the tiles we propose a greedy approach for adaptive tiling where larger tiles are placed in homogenous image regions. By this we avoid the visual periodicity, which is induced by the equal spacing of the image tiles in the completely regular setting. Our overall system addresses also the cleaning of the image database by removing all unwanted images with no meaningful content. We apply differently sophisticated image descriptors to find the best matching image for each tile. For esthetic and artistic reasons we classify each tile as "feature" or "non-feature" and then apply a suitable image descriptor. In a user study we have verified that our descriptors lead to mosaics that are significantly better recognizable than just taking, e.g., average color values.
A WebService employing this method is available.
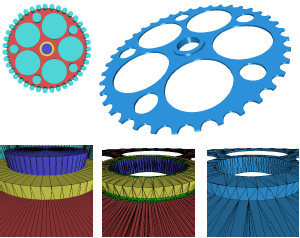
High-Resolution Volumetric Computation of Offset Surfaces with Feature Preservation
We present a new algorithm for the efficient and reliable generation of offset surfaces for polygonal meshes. The algorithm is robust with respect to degenerate configurations and computes (self-)intersection free offsets that do not miss small and thin components. The results are correct within a prescribed e-tolerance. This is achieved by using a volumetric approach where the offset surface is defined as the union of a set of spheres, cylinders, and prisms instead of surface-based approaches that generally construct an offset surface by shifting the input mesh in normal direction. Since we are using the unsigned distance field, we can handle any type of topological inconsistencies including non-manifold configurations and degenerate triangles. A simple but effective mesh operation allows us to detect and include sharp features (shocks) into the output mesh and to preserve them during post-processing (decimation and smoothing). We discretize the distance function by an efficient multi-level scheme on an adaptive octree data structure. The problem of limited voxel resolutions inherent to every volumetric approach is avoided by breaking the bounding volume into smaller tiles and processing them independently. This allows for almost arbitrarily high voxel resolutions on a commodity PC while keeping the output mesh complexity low. The quality and performance of our algorithm is demonstrated for a number of challenging examples.
2D Video Editing for 3D Effects

We present a semi-interactive system for advanced video processing and editing. The basic idea is to partially recover planar regions in object space and to exploit this minimal pseudo-3D information in order to make perspectively correct modifications. Typical operations are to increase the quality of a low-resolution video by overlaying high-resolution photos of the same approximately planar object or to add or remove objects by copying them from other video streams and distorting them perspectively according to some planar reference geometry. The necessary user interaction is entirely in 2D and easy to perform even for untrained users. The key to our video processing functionality is a very robust and mostly automatic algorithm for the perspective registration of video frames and photos, which can be used as a very effective video stabilization tool even in the presence of fast and blurred motion. Explicit 3D reconstruction is thus avoided and replaced by image and video rectification. The technique is based on state-of-the-art feature tracking and homography matching. In complicated and ambiguous scenes, user interaction as simple as 2D brush strokes can be used to support the registration. In the stabilized video, he reference plane appears frozen which simplifies segmentation and matte extraction. We demonstrate our system for a number of quite challenging application scenarios such as video enhancement, background replacement, foreground removal and perspectively correct video cut and paste.
Interactive Image Completion with Perspective Correction

We present an interactive system for fragment-based image completion which exploits information about the approximate 3D structure in a scene in order to estimate and apply perspective corrections when copying a source fragment to a target position. Even though implicit 3D information is used, the interaction is strictly 2D which makes the user interface very simple and intuitive. We propose different interaction metaphors in our system for providing 3D information interactively. Our search and matching procedure is done in the Fourier domain and hence it is very fast and it allows us to use large fragments and multiple source images with high resolution while still obtaining interactive response times. Our image completion technique also takes user-specified structure information into account where we generalize the concept of feature curves to arbitrary sets of feature pixels. We demonstrate our technique on a number of difficult completion tasks.
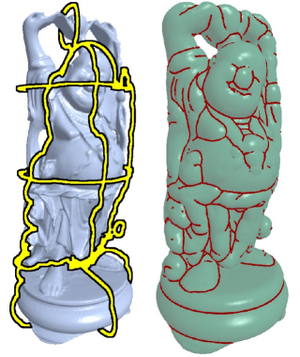
Automatic Restoration of Polygon Models

We present a fully automatic technique which converts an inconsistent input mesh into an output mesh that is guaranteed to be a clean and consistent mesh representing the closed manifold surface of a solid object. The algorithm removes all typical mesh artifacts such as degenerate triangles, incompatible face orientation, non-manifold vertices and edges, overlapping and penetrating polygons, internal redundant geometry as well as gaps and holes up to a user-defined maximum size. Moreover, the output mesh always stays within a prescribed tolerance to the input mesh. Due to the effective use of a hierarchical octree data structure, the algorithm achieves high voxel resolution (up to 4096^3 on a 2GB PC) and processing times of just a few minutes for moderately complex objects. We demonstrate our technique on various architectural CAD models to show its robustness and reliability.
