
Profile

|
Dr. Dominik Sibbing |
Publications
Data Driven 3D Face Tracking Based on a Facial Deformation Model

We introduce a new markerless 3D face tracking approach for 2D video streams captured by a single consumer grade camera. Our approach is based on tracking 2D features in the video and matching them with the projection of the corresponding feature points of a deformable 3D model. By this we estimate the initial shape and pose of the face. To make the tracking and reconstruction more robust we add a smoothness prior for pose changes as well as for deformations of the faces. Our major contribution lies in the formulation of the smooth deformation prior which we derive from a large database of previously captured facial animations showing different (dynamic) facial expressions of a fairly large number of subjects. We split these animation sequences into snippets of fixed length which we use to predict the facial motion based on previous frames. In order to keep the deformation model compact and independent from the individual physiognomy, we represent it by deformation gradients (instead of vertex positions) and apply a principal component analysis in deformation gradient space to extract the major modes of facial deformation. Since the facial deformation is optimized during tracking, it is particularly easy to apply them to other physiognomies and thereby re-target the facial expressions. We demonstrate the effectiveness of our technique on a number of examples.
VMV 2015 Honorable Mention
Nonparametric Facial Feature Localization Using Segment-Based Eigenfeatures
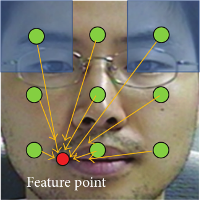
We present a nonparametric facial feature localization method using relative directional information between regularly sampled image segments and facial feature points. Instead of using any iterative parameter optimization technique or search algorithm, our method finds the location of facial feature points by using a weighted concentration of the directional vectors originating from the image segments pointing to the expected facial feature positions. Each directional vector is calculated by linear combination of eigendirectional vectors which are obtained by a principal component analysis of training facial segments in feature space of histogram of oriented gradient (HOG). Our method finds facial feature points very fast and accurately, since it utilizes statistical reasoning from all the training data without need to extract local patterns at the estimated positions of facial features, any iterative parameter optimization algorithm, and any search algorithm. In addition, we can reduce the storage size for the trained model by controlling the energy preserving level of HOG pattern space.
Efficient Enforcement of Hard Articulation Constraints in the Presence of Closed Loops and Contacts
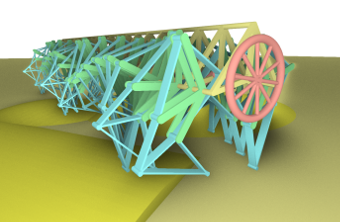
In rigid body simulation, one must distinguish between contacts (so-called unilateral constraints) and articulations (bilateral constraints). For contacts and friction, iterative solution methods have proven most useful for interactive applications, often in combination with Shock-Propagation in cases with strong interactions between contacts (such as stacks), prioritizing performance and plausibility over accuracy. For articulation constraints, direct solution methods are preferred, because one can rely on a factorization with linear time complexity for tree-like systems, even in ill-conditioned cases caused by large mass-ratios or high complexity. Despite recent advances, combining the advantages of direct and iterative solution methods wrt. performance has proven difficult and the intricacy of articulations in interactive applications is often limited by the convergence speed of the iterative solution method in the presence of closed kinematic loops (i.e. auxiliary constraints) and contacts. We identify common performance bottlenecks in the dynamic simulation of unilateral and bilateral constraints and are able to present a simulation method, that scales well in the number of constraints even in ill-conditioned cases with frictional contacts, collisions and closed loops in the kinematic graph. For cases where many joints are connected to a single body, we propose a technique to increase the sparsity of the positive definite linear system. A solution to these bottlenecks is presented in this paper to make the simulation of a wider range of mechanisms possible in real-time without extensive parameter tuning.
Interactive Volume-Based Visualization and Exploration for Diffusion Fiber Tracking
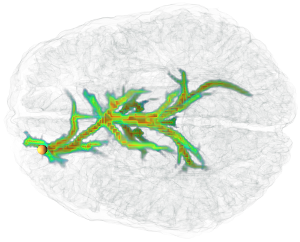
We present a new method to interactively compute and visualize fiber bundles extracted from a diffusion magnetic resonance image. It uses Dijkstra's shortest path algorithm to find globally optimal pathways from a given seed to all other voxels. Our distance function enables Dijkstra to generalize to larger voxel neighborhoods, resulting in fewer quantization artifacts of the orientations, while the shortest paths are still efficiently computable. Our volumetric fiber representation enables the usage of volume rendering techniques. Therefore no complicated pruning or analysis of the resulting fiber tree is needed in order to visualize important fibers. In fact, this can efficiently be done by changing a transfer function. Our application is highly interactive, allowing the user to focus completely on the exploration of the data.
SIFT-Realistic Rendering

3D localization approaches establish correspondences between points in a query image and a 3D point cloud reconstruction of the environment. Traditionally, the database models are created from photographs using Structure-from-Motion (SfM) techniques, which requires large collections of densely sampled images. In this paper, we address the question how point cloud data from terrestrial laser scanners can be used instead to significantly reduce the data collection effort and enable more scalable localization.
The key change here is that, in contrast to SfM points, laser-scanned 3D points are not automatically associated with local image features that could be matched to query image features. In order to make this data usable for image-based localization, we explore how point cloud rendering techniques can be leveraged to create virtual views from which database features can be extracted that match real image-based features as closely as possible. We propose different rendering techniques for this task, experimentally quantify how they affect feature repeatability, and demonstrate their benefit for image-based localization.
Topology aware Quad Dominant Meshing for Vascular Structures
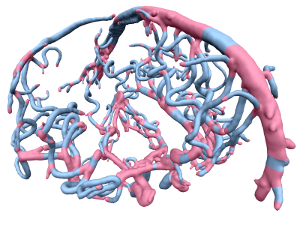
We present a pipeline to generate high quality quad dominant meshes for vascular structures from a given volumetric image. As common for medical image segmentation we use a Level Set approach to separate the region of interest from the background. However in contrast to the standard method we control the topology of the deformable object – defined by the Level Set function – which allows us to extract a proper skeleton which represents the global topological information of the vascular structure. Instead of solving a complex global optimization problem to compute a quad mesh, we divide the problem and partition the complex model into junction and tube elements, employing the skeleton of the vascular structure. After computing quad meshes for the junctions using the Mixed Integer Quadrangulation approach, we re-mesh the tubes using an algorithm inspired by the well known Bresenham Algorithm for drawing lines which distributes irregular elements equally over the entire tube element.
Markerless Reconstruction and Synthesis of Dynamic Facial Expressions
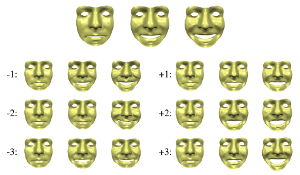
In this paper we combine methods from the field of computer vision with surface editing techniques to generate animated faces, which are all in full correspondence to each other. The inputs for our system are synchronized video streams from multiple cameras. The system produces a sequence of triangle meshes with fixed connectivity, representing the dynamics of the captured face. By carefully taking all requirements and characteristics into account we decided for the proposed system design: We deform an initial face template using movements estimated from the video streams. To increase the robustness of the reconstruction, we use a morphable model as a shape prior to initialize a surfel fitting technique which is able to precisely capture face shapes not included in the morphable model. In the deformation stage, we use a 2D mesh-based tracking approach to establish correspondences over time. We then reconstruct positions in 3D using the same surfel fitting technique, and finally use the reconstructed points to robustly deform the initially reconstructed face.
This paper is an extended version of our paper "Markerless Reconstruction of Dynamic Facial Expressions" which was published 2009 at 3-D Digital Imaging and Modeling. Besides describing the reconstruction of human faces in more detail we demonstrate the applicability of the tracked face template for automatic modeling and show how to use deformation transfer to attenuate expressions, blend expressions or how to build a statistical model, similar to a morphable model, on the dynamic movements.
Image Synthesis for Branching Structures

We present a set of techniques for the synthesis of artificial images that depict branching structures like rivers, cracks, lightning, mountain ranges, or blood vessels. The central idea is to build a statistical model that captures the characteristic bending and branching structure from example images. Then a new skeleton structure is synthesized and the final output image is composed from image fragments of the original input images. The synthesis part of our algorithm runs mostly automatic but it optionally allows the user to control the process in order to achieve a specific result. The combination of the statistical bending and branching model with sophisticated fragment-based image synthesis corresponds to a multi-resolution decomposition of the underlying branching structure into the low frequency behavior (captured by the statistical model) and the high frequency detail (captured by the image detail in the fragments). This approach allows for the synthesis of realistic branching structures, while at the same time preserving important textural details from the original image.
Markerless Reconstruction of Dynamic Facial Expressions
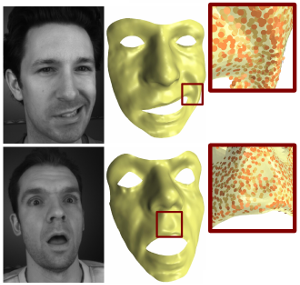
In this paper we combine methods from the field of computer vision with surface editing techniques to generate animated faces, which are all in full correspondence to each other. The input for our system are synchronized video streams from multiple cameras. The system produces a sequence of triangle meshes with fixed connectivity, representing the dynamics of the captured face. By carfully taking all requirements and characteristics into account we decided for the proposed system design: We deform an initial face template using movements estimated from the video streams. To increase the robustness of the initial reconstruction, we use a morphable model as a shape prior. However using an efficient Surfel Fitting technique, we are still able to precisely capture face shapes not part of the PCA Model. In the deformation stage, we use a 2D mesh-based tracking approach to establish correspondences in time. We then reconstruct image-samples in 3D using the same Surfel Fitting technique, and finally use the reconstructed points to robustly deform the initially reconstructed face.
Fast Interactive Region of Interest Selection for Volume Visualization
We describe a new method to support the segmentation of a volumetric MRI- or CT-dataset such that only the components selected by the user are displayed by a volume renderer for visual inspection. The goal is to combine the advantages of direct volume rendering (high efficiency and semi-transparent display of internal structures) and indirect volume rendering (well defined surface geometry and topology). Our approach is based on a re-labeling of the input volume's set of isosurfaces which allows the user to peel off the outer layers and to distinguish unconnected voxel components which happen to have the same voxel values. For memory and time efficiency, isosurfaces are never generated explicitly. Instead a second voxel grid is computed which stores a discretization of the new isosurface labels. Hence the masking of unwanted regions as well as the direct volume rendering of the desired regions of interest (ROI) can be implemented on the GPU which enables interactive frame rates even while the user changes the selection of the ROI.
