
Profile

|
Publications
Linear Analysis of Nonlinear Constraints for Interactive Geometric Modeling
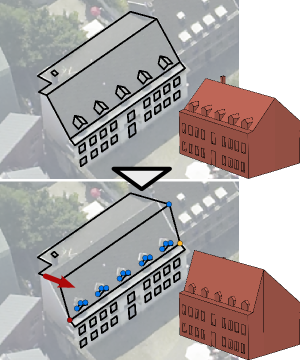
Thanks to its flexibility and power to handle even complex geometric relations, 3D geometric modeling with nonlinear constraints is an attractive extension of traditional shape editing approaches. However, existing approaches to analyze and solve constraint systems usually fail to meet the two main challenges of an interactive 3D modeling system: For each atomic editing operation, it is crucial to adjust as few auxiliary vertices as possible in order to not destroy the user's earlier editing effort. Furthermore, the whole constraint resolution pipeline is required to run in real-time to enable a fluent, interactive workflow. To address both issues, we propose a novel constraint analysis and solution scheme based on a key observation: While the computation of actual vertex positions requires nonlinear techniques, under few simplifying assumptions the determination of the minimal set of to-be-updated vertices can be performed on a linearization of the constraint functions. Posing the constraint analysis phase as the solution of an under-determined linear system with as few non-zero elements as possible enables us to exploit an efficient strategy for the Cardinality Minimization problem known from the field of Compressed Sensing, resulting in an algorithm capable of handling hundreds of vertices and constraints in real-time. We demonstrate at the example of an image-based modeling system for architectural models that this approach performs very well in practical applications.
Awards:
Markerless Reconstruction and Synthesis of Dynamic Facial Expressions
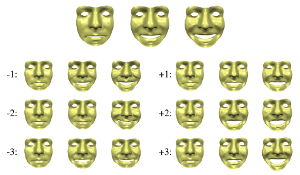
In this paper we combine methods from the field of computer vision with surface editing techniques to generate animated faces, which are all in full correspondence to each other. The inputs for our system are synchronized video streams from multiple cameras. The system produces a sequence of triangle meshes with fixed connectivity, representing the dynamics of the captured face. By carefully taking all requirements and characteristics into account we decided for the proposed system design: We deform an initial face template using movements estimated from the video streams. To increase the robustness of the reconstruction, we use a morphable model as a shape prior to initialize a surfel fitting technique which is able to precisely capture face shapes not included in the morphable model. In the deformation stage, we use a 2D mesh-based tracking approach to establish correspondences over time. We then reconstruct positions in 3D using the same surfel fitting technique, and finally use the reconstructed points to robustly deform the initially reconstructed face.
This paper is an extended version of our paper "Markerless Reconstruction of Dynamic Facial Expressions" which was published 2009 at 3-D Digital Imaging and Modeling. Besides describing the reconstruction of human faces in more detail we demonstrate the applicability of the tracked face template for automatic modeling and show how to use deformation transfer to attenuate expressions, blend expressions or how to build a statistical model, similar to a morphable model, on the dynamic movements.
Automatic Registration of Oblique Aerial Images with Cadastral Maps
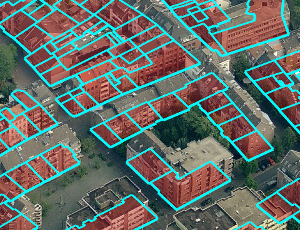
In recent years, oblique aerial images of urban regions have become increasingly popular for 3D city modeling, texturing, and various cadastral applications. In contrast to images taken vertically to the ground, they provide information on building heights, appearance of facades, and terrain elevation. Despite their widespread availability for many cities, the processing pipeline for oblique images is not fully automatic yet. Especially the process of precisely registering oblique images with map vector data can be a tedious manual process. We address this problem with a registration approach for oblique aerial images that is fully automatic and robust against discrepancies between map and image data. As input, it merely requires a cadastral map and an arbitrary number of oblique images. Besides rough initial registrations usually available from GPS/INS measurements, no further information is required, in particular no information about the terrain elevation.
Character Reconstruction and Animation from Uncalibrated Video

We present a novel method to reconstruct 3D character models from video. The main conceptual contribution is that the reconstruction can be performed from a single uncalibrated video sequence which shows the character in articulated motion. We reduce this generalized problem setting to the easier case of multi-view reconstruction of a rigid scene by applying pose synchronization of the character between frames. This is enabled by two central technical contributions. First, based on a generic character shape template, a new mesh-based technique for accurate shape tracking is proposed. This method successfully handles the complex occlusions issues, which occur when tracking the motion of an articulated character. Secondly, we show that image-based 3D reconstruction becomes possible by deforming the tracked character shapes as-rigid-as-possible into a common pose using motion capture data. After pose synchronization, several partial reconstructions can be merged in order to create a single, consistent 3D character model. We integrated these components into a simple interactive framework, which allows for straightforward generation and animation of 3D models for a variety of character shapes from uncalibrated monocular video.
Markerless Reconstruction of Dynamic Facial Expressions
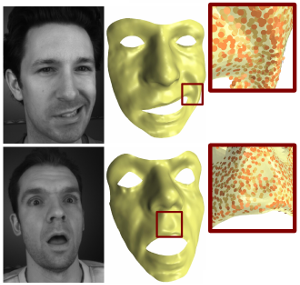
In this paper we combine methods from the field of computer vision with surface editing techniques to generate animated faces, which are all in full correspondence to each other. The input for our system are synchronized video streams from multiple cameras. The system produces a sequence of triangle meshes with fixed connectivity, representing the dynamics of the captured face. By carfully taking all requirements and characteristics into account we decided for the proposed system design: We deform an initial face template using movements estimated from the video streams. To increase the robustness of the initial reconstruction, we use a morphable model as a shape prior. However using an efficient Surfel Fitting technique, we are still able to precisely capture face shapes not part of the PCA Model. In the deformation stage, we use a 2D mesh-based tracking approach to establish correspondences in time. We then reconstruct image-samples in 3D using the same Surfel Fitting technique, and finally use the reconstructed points to robustly deform the initially reconstructed face.
An Intuitive Interface for Interactive High Quality Image-Based Modeling
(Proc. of Pacific Graphics 2009)

We present the design of an interactive image-based modeling tool that enables a user to quickly generate detailed 3D models with texture from a set of calibrated input images. Our main contribution is an intuitive user interface that is entirely based on simple 2D painting operations and does not require any technical expertise by the user or difficult pre-processing of the input images. One central component of our tool is a GPU-based multi-view stereo reconstruction scheme, which is implemented by an incremental algorithm, that runs in the background during user interaction so that the user does not notice any significant response delay.
2D Video Editing for 3D Effects

We present a semi-interactive system for advanced video processing and editing. The basic idea is to partially recover planar regions in object space and to exploit this minimal pseudo-3D information in order to make perspectively correct modifications. Typical operations are to increase the quality of a low-resolution video by overlaying high-resolution photos of the same approximately planar object or to add or remove objects by copying them from other video streams and distorting them perspectively according to some planar reference geometry. The necessary user interaction is entirely in 2D and easy to perform even for untrained users. The key to our video processing functionality is a very robust and mostly automatic algorithm for the perspective registration of video frames and photos, which can be used as a very effective video stabilization tool even in the presence of fast and blurred motion. Explicit 3D reconstruction is thus avoided and replaced by image and video rectification. The technique is based on state-of-the-art feature tracking and homography matching. In complicated and ambiguous scenes, user interaction as simple as 2D brush strokes can be used to support the registration. In the stabilized video, he reference plane appears frozen which simplifies segmentation and matte extraction. We demonstrate our system for a number of quite challenging application scenarios such as video enhancement, background replacement, foreground removal and perspectively correct video cut and paste.
LaserBrush: A Flexible Device for 3D Reconstruction of Indoor Scenes

While many techniques for the 3D reconstruction of small to medium sized objects have been proposed in recent years, the reconstruction of entire scenes is still a challenging task. This is especially true for indoor environments where existing active reconstruction techniques are usually quite expensive and passive, image-based techniques tend to fail due to high scene complexities, difficult lighting situations, or shiny surface materials. To fill this gap we present a novel low-cost method for the reconstruction of depth maps using a video camera and an array of laser pointers mounted on a hand-held rig. Similar to existing laser-based active reconstruction techniques, our method is based on a fixed camera, moving laser rays and depth computation by triangulation. However, unlike traditional methods, the position and orientation of the laser rig does not need to be calibrated a-priori and no precise control is necessary during image capture. The user rather moves the laser rig freely through the scene in a brush-like manner, letting the laser points sweep over the scene's surface. We do not impose any constraints on the distribution of the laser rays, the motion of the laser rig, or the scene geometry except that in each frame at least six laser points have to be visible. Our main contributions are two-fold. The first is the depth map reconstruction technique based on irregularly oriented laser rays that, by exploiting robust sampling techniques, is able to cope with missing and even wrongly detected laser points. The second is a smoothing operator for the reconstructed geometry specifically tailored to our setting that removes most of the inevitable noise introduced by calibration and detection errors without damaging important surface features like sharp edges.
City Virtualization

Virtual city models become more and more important in applications like virtual city guides, geographic information systems or large scale visualizations, and also play an important role during the design of wireless networks and the simulation of noise distribution or environmental phenomena. However, generating city models of sufficient quality with respect to different target applications is still an extremely challenging, time consuming and costly process. To improve this situation, we present a novel system for the rapid and easy creation of 3D city models from 2D map data and terrain information, which is available for many cities in digital form. Our system allows to continuously vary the resulting level of correctness, ranging from models with high-quality geometry and plausible appearance which are generated almost completely automatic to models with correctly textured facades and highly detailed representations of important, well known buildings which can be generated with reasonable additional effort. While our main target application is the high-quality, real-time visualization of complex, detailed city models, the models generated with our approach have successfully been used for radio wave simulations as well. To demonstrate the validity of our approach, we show an exemplary reconstruction of the city of Aachen.
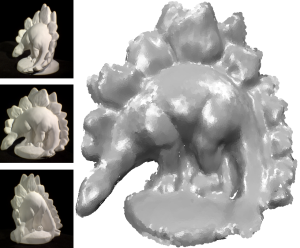
A Surface-Growing Approach to Multi-View Stereo Reconstruction

We present a new approach to reconstruct the shape of a 3D object or scene from a set of calibrated images. The central idea of our method is to combine the topological flexibility of a point-based geometry representation with the robust reconstruction properties of scene-aligned planar primitives. This can be achieved by approximating the shape with a set of surface elements (surfels) in the form of planar disks which are independently fitted such that their footprint in the input images matches. Instead of using an artificial energy functional to promote the smoothness of the recovered surface during fitting, we use the smoothness assumption only to initialize planar primitives and to check the feasibility of the fitting result. After an initial disk has been found, the recovered region is iteratively expanded by growing further disks in tangent direction. The expansion stops when a disk rotates by more than a given threshold during the fitting step. A global sampling strategy guarantees that eventually the whole surface is covered. Our technique does not depend on a shape prior or silhouette information for the initialization and it can automatically and simultaneously recover the geometry, topology, and visibility information which makes it superior to other state-of-the-art techniques. We demonstrate with several high-quality reconstruction examples that our algorithm performs highly robustly and is tolerant to a wide range of image capture modalities.
Iterative Multi-View Plane Fitting
We present a method for the reconstruction of 3D planes from calibrated 2D images. Given a set of pixels Ω in a reference image, our method computes a plane which best approximates that part of the scene which has been projected to Ω by exploiting additional views. Based on classical image alignment techniques we derive linear matching equations minimally parameterized by the three parameters of an object-space plane. The resulting iterative algorithm is highly robust because it is able to integrate over large image regions due to the correct object-space approximation and hence is not limited to comparing small image patches. Our method can be applied to a pair of stereo images but is also able to take advantage of the additional information provided by an arbitrary number of input images. A thorough experimental validation shows that these properties enable robust convergence especially under the influence of image sensor noise and camera calibration errors.
